
Word-Distance vs. Idea-Distance
The case for lanoitaring
Defining Word-Distance
There’s a concept in information theory called Hamming Distance. Without delving too deeply into the theory, Hamming distance is a way of describing how different two sequences of characters are.
Take the two character sequences (in this case a series of bits) 11110000 and 11001100.
How different are they?
Their Hamming distance is defined, as per Wikipedia, as
the number of positions at which the corresponding symbols are different.
So we line up the two series of bits, and compare them character by character:
11110000
11001100
I’ve bolded and italicized the characters that are different.
In this case there are four of them, and so we say that the Hamming distance between the two bit strings is four.
With the idea of Hamming distance, we can envision something we might call word-space: the collection of all possible words, each separated from the next by its Hamming distance (or some analogous measurement). The words “call” and “cell” might be close to one another in word-space, only differing in a single character, whereas both words would be far away from a word like “disingenuous” or “Machiavellian”.
Defining Idea-Distance
Analogous to word-distance, we might imagine something like idea-distance. While it seems difficult to precisely define or enumerate how different two ideas are from one another, relative measurements can be used to achieve a similar effect.
Take the idea of a “city,” for instance. Is a “city” more like a “town” or a “banana”? Obviously a “city” is more like a “town,” so “city” would be closer to “town” in idea-space than to “banana”, or “Marxism”, or “aquaculture”.
Using Distant Words For Distant Ideas
Hamming distance is used when designing and selecting error-correction codes. The idea is that communication isn’t perfect - information gets lost when transferring it from one place to another.
Thus it becomes important to make sure that the message you’re sending can’t be easily mistaken for another, similar message.
Imagine that you’re sending an important message to someone, and that important message is binary in nature - it’s a yes/no, go/no-go kind of communication. Maybe it’s the final confirmation to launch a military operation, or an RSVP to a wedding (yes, I’m coming or no, I’m not coming). Either way, the message itself contains only one bit of information. It can be transmitted as a single 0 or 1: 0 for no-go, do not launch the operation, 1 for go ahead, begin the operation.
So we have:
0 → no go
1 → go
But there’s a risk here that the communication itself is imperfect. Electronics malfunction, code has bugs, and occasionally cosmic rays screw up computer memory. And that’s just for electronic communication - how many times have you misheard someone in a conversation, especially with loud background noise?
In electronics, turning a single 0 into a 1 is not an uncommon error. So how should we transmit our message to reduce the odds of a miscommunication?
Easy - we increase the Hamming distance between the two messages. 0 and 1 only have a Hamming distance of one. What if, instead of using 0 and 1, we used something else instead?
How about:
00 → no go
11 → go
Now we have a Hamming distance of two, which is better, but there’s still a problem. If one bit gets flipped in transmission, the message sent will be either 01 or 10. Imagine you’re waiting to receive your orders - launch the operation or cancel, either 11 or 00, and instead you receive 01.
What are you supposed to do with that? 01 could be a corrupted version of either intended communication; 00 → 01 or 11 → 01, with equal probability.
So let’s increase the Hamming distance further:
000 → no go
111 → go
The Hamming distance is three here, and at last we have some real redundancy. A single bit flip in transmission will result in a received message consisting of either two zeros and a single one, or two ones and a single zero.
For instance, if the operation is called off and the message 000 is transmitted, a single error in transmission will result in either 100, 010, or 001. Looking at that message, it becomes much more likely that the original message was 000 than 111. The odds of a successful communication, even in the case of transmission error, rises.
For those of you who want a little bit more math, if there’s a 10% chance of a transmission error (any single bit being flipped):
Transmitted → Received correct message or received detectable error probability
0 or 1 → 90% (10% chance the bit got flipped in transit, but note that an error is also not detectable; if a bit did get flipped, the receiver has no way to tell.)
00 or 11 → 99% (81% chance message is correctly received, 18% one bit gets flipped and an error is detected, 1% both get flipped.)
000 or 111 → 99.9% (72.9% chance message is correctly received, 24.3% chance that one bit got flipped, 2.7% chance that two bits got flipped, and 0.1% chance that all three bits get flipped.)
And so on.
We see here that communicating with words farther apart in word-space reduces the odds of a miscommunication, even in the event of transmission error.1
So what about non-electronic, non-bit communication?
Ordinary Language
In ordinary language, there isn’t any governing body to decide exactly what words mean what ideas - the whole language evolves and grows, and even those who write the dictionaries are more capturing existing phenomenon than deciding what is or is not a part of the language.
Ideally, the word-distance between two words in a language would be correlated to the idea-distance between the ideas they represent. Words that sound more alike would mean similar things, and words that sounds and look nothing alike would mean very different things.2
If we were to plot the word-distance versus idea-distance for each pair of words in an ideal language, these pairs of (word-distance, idea-distance) might look like so:
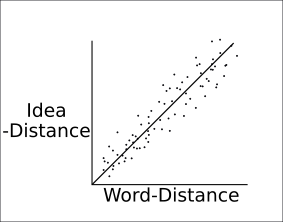
Where each dot represents a pair of words (e.g. fire + water), and is located on the graph by [x, y] coordinates determined by [word-distance(fire, water), idea-distance(fire, water)].
While I can’t speak for other natural languages, English in particular is something of a mess. Without any rigorous study, my guess for what English would look like is something like this:

With no correlation whatsoever between word-distance and idea-distance.
There are two quadrants of concern here; two areas on this graph where word-distance and idea-distance are uncorrelated to a degree that miscommunication becomes, not just easy, but arguably easier than correct communication.
Those two areas are the top left and bottom right:

The bottom right is full of words that are low in idea-distance but high in word-distance - put simply, they sound different but refer to similar ideas. Most synonyms in English work this way, and while it makes English vocabulary a pain to learn, it doesn’t really interfere with communication. Here we find word pairs like “robot” and “machine”, or “hurricane” and “storm”.
The real problem arises from word pairs in the top left: words that sound alike, but mean very different things, and it’s these that we’ll focus on.
Examples
Many of the most confusing pieces of the English language reside in the top left quadrant of the above graph, where words look and/or sound alike but mean very different things.
Common
Some common examples are well-known homophones:
Two, Too, To
Two is a number
Too means “also” or “as well”
To is a preposition indicating a direction
There, They’re, Their
There is a location
They’re is a contraction of “they are”
Their is a possessive referring to multiple people (or to people without reference to gender)
Specific
But there are less well-known examples as well, and they can be much more pernicious:
Solitary, Solidarity
Solitary refers to being alone
Solidarity is about mutual support with others
Solitary and Solidarity are very close in word-space, but mean almost the opposite from one another!
Prodigal, Prodigy
Prodigal refers to being wasteful with money
Prodigy refers to having exceptional abilities
This is a particularly common mistake/miscommunication - I’ve often seen the phrase “prodigal son” (as in, “The prodigal son returns!”) used in a context suggesting the author thought that “prodigal” was a way to describe a prodigy.
Again, Against
Again refers to repetition or copying
Against refers to opposition or resistance
Here we see that adding two letters completely changes the meaning of the word while only barely changing the spelling or pronunciation.
Jargon
This phenomenon is especially frustrating when it shows up in jargon - precise language used in a particular specialty. This is frustrating because jargon is designed in a way that the general language is not; someone created these definitions on purpose, and they seed confusion where none need exist.
In Economics: “A change in demand”, “A change in the quantity demanded”3
“A change in demand” refers to a change in the demand curve itself, wherein the nature of a market has been altered
“A change in the quantity demanded” refers to a parameter changing in a static market
In Programming: “Overloading”, “Overriding”
“Overloading” is when multiple methods in the same class have the same name but different parameters
“Overriding” is when a child class has the same method name and parameters as its parent class
Rational vs Rationalizing
Lastly, I’d like to bring up perhaps the most frustrating case of two words being adjacent in word-space and far apart in idea-space that I personally deal with: rational and rationalizing.
While the two words are quite close in word-space (rational being a strict subset of rationalizing), they refer to thought processes that are diametrically opposed from one another.
I’d encourage anyone interested in the difference between being rational and rationalizing to read Eliezer Yudkowky’s essay on the topic, but I’ll summarize here.
Being rational refers to a thought process wherein evidence is used to reach a conclusion. It means that, before any conclusion is reached, a genuine effort is made to search for and evaluate any factors that might make one possible conclusion more likely than another. Being rational means following the evidence to the conclusion said evidence suggests is most likely.
Rationalizing, on the other hand, is a thought process wherein a conclusion is chosen preemptively, before any evidence is examined, and then locating pieces of evidence in order to retroactively defend the chosen conclusion.
It is rational to evaluate evidence and reach a conclusion; it is rationalizing to reach for evidence after one’s mind is made up. Rationalizing is a mind’s attempt to appear rational when it has been anything but. It is the acknowledgement that beliefs and conclusions ought to be arrived at through evidence when nothing of the sort has happened. It is the pretense of using evidence when in fact evidence has been used, twisted and forced to point to any conclusion the user decrees.
One is rational to reach a conclusion; one rationalizes to justify a conclusion.
These two thought processes are the opposite of one another, and yet their adjacency in word-space means that any attempt to defend one’s thought process as rational is vulnerable to the accusation of rationalizing by those unaware of the gulf dividing the two words.
All of this is greatly exacerbated by just how alike these two words are, how close they are in word-space.
Conclusion: Lanoitaring
I prefer to conclude on a positive note, or at least a productive one. I am affably evil, after all, not depressingly evil.
To do so, I would like to suggest a new word that we can use instead of “rationalizing”, one that is much further in word-space from “rational” and captures the essence of the idea that “rational” and “rationalizing” are opposites.
I hereby suggest the word “lanoitaring” inherit the meaning we once ascribed to “rationalizing”, and replace the word in our vocabulary.
And if you wonder why I chose “lanoitaring” - well, follow the evidence. That’s what I did!
This is the reason for the NATO phonetic alphabet, which specifies how each letter and digit in English should be pronounced. When transmitting military codes, coordinates, or other information, simple mistakes can be disastrous, so each letter and number must be impossible to mistake for any of the others.
The English language, by default, has plenty of letters that sound like one another - “M” and “N” both begin with the soft “eh” sound, and “B” “C” “D” “E” “G” “P” “T” “V” and “Z” all end with the hard “ee” sound. When communicating over a crackling radio or with shells and gunfire in the background, mistaking one letter for another is frighteningly easy.
So the NATO phonetic alphabet specifies how to communicate each letter such that it is unmistakable for any other letter - in other words, such that each letter’s pronunciation is sufficiently distant from each other letter that the odds of a miscommunication are minimal. “M” becomes “Mike” and “N” becomes “November”; I find it hard to imagine even the most chaotic background noise transforming “Mike” into “November”.
There is sort of an exception here: word modifiers. “Anti”, for instance, is a prefix that modifies a word to mean its opposite. Disestablishmentarians and antidisestablishmentarians find themselves reasonably close in word-space, but opposite in idea-space, and this is understandable, although still not ideal when it comes to communicating over lossy channels. We’ll ignore word-modifiers in the rest of the text for simplicity.
Here a phrase is used instead of a word, but the concept of word-distance applies just as well to phrases as it does to words. “A change in demand” and “a change in the quantity demanded” are very similar phrases, and my Econ 101 textbook spends a great deal of text insisting that the reader not confuse one for the other.
Good idea, a couple of small quabbles:
1. I am a bit confused why you would use Hamming distance (which is limited to same-length words) over Levenshtein distance.
2. Antonyms are indeed quite close in concept-space. Both pro-abortion and anti-abortion are concepts about stance regarding abortion, rather than, to borrow Carroll's example, ravens or desks.